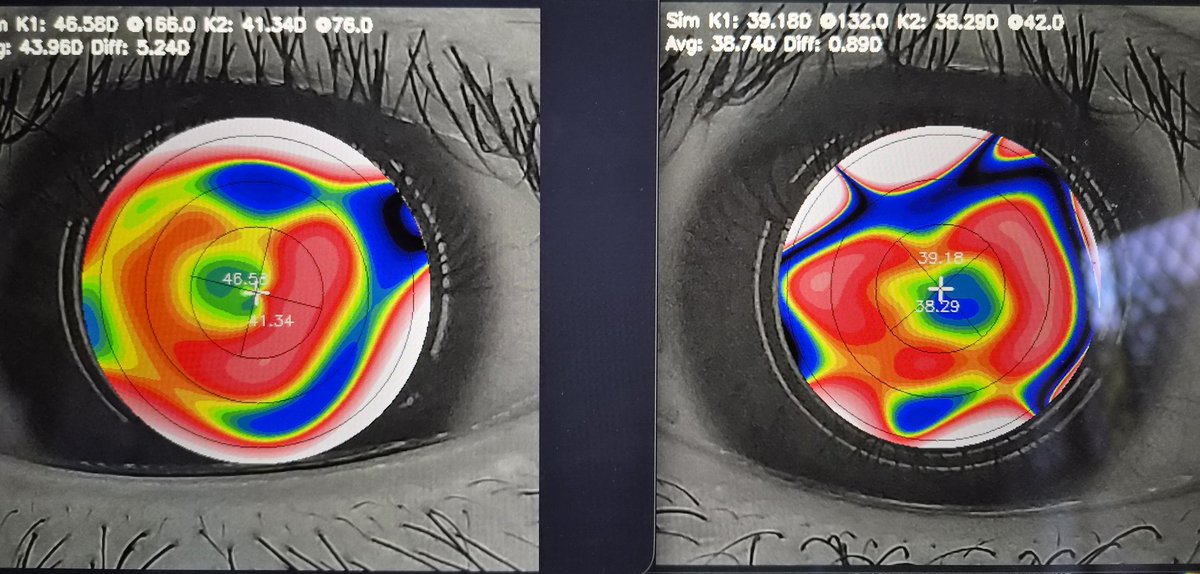
在上一篇文章中我說了我配戴 OK 鏡的過程,在整個過程中,我發現最煩人的就是這張角膜地形圖了。因為這必須要用那個非常昂貴且巨大的設備才能拍攝。尤其是在我靠眼罩壓鏡片的那段時間,如果能每天都得到這個角膜地形圖的回饋,我就可以立即知道哪裡出了問題。後來我發現,還真有這樣的解決方案:HTTPS://github.com/microsoft/SmartKC-A-Smartphone-based-Corn[……]
在上一篇文章中我說了我配戴 OK 鏡的過程,在整個過程中,我發現最煩人的就是這張角膜地形圖了。因為這必須要用那個非常昂貴且巨大的設備才能拍攝。尤其是在我靠眼罩壓鏡片的那段時間,如果能每天都得到這個角膜地形圖的回饋,我就可以立即知道哪裡出了問題。後來我發現,還真有這樣的解決方案:HTTPS://github.com/microsoft/SmartKC-A-Smartphone-based-Corn[……]

我決定要戴 OK 鏡是在去年(2025)年中的時候,那時候我已經連續戴隱形眼鏡兩三年了。我是那種成年後近視度數依舊在漲的類型,自從畢業上班以來,基本上就是一年 100 度的穩定上漲。
契機是有一天送女票去看醫生的時候發現眼睛突然出血,就去約了眼睛檢查。雖然出血這個事情本身沒什麼大事,但順便驗光發現──我的度數又漲了。如今我已經雙眼各 675 程度,再不控制的話,可能真的會瞎?
於[……]
https://github.com/milla-jovovich/mempalace 是最近比較火的一個本地 AI Agent 記憶系統,它比較創新的引入了記憶宮殿的概念,完全離線。看起來非常美好,但由於程式碼是用 python 寫的,要整合到 mac agent裡還是有點複雜,這裡我記錄安裝過程:
如果你透過 brew 安裝了新版的 python,那麼除[……]
macOS 已經更新到 26 了, 但對於第三方輸入法的支持一直沒有任何變化,最新的 Xcode 26 破壞了之前我一直用的方法——直接把編譯路徑改到 /庫/輸入法 現在這麼做 xcode 會報錯,因為項目依賴的 framework 不會再寫到這個目錄了。
只有去掉所有更改編譯目錄的設置後編譯就可以成功。我猜大概是因為新版的 SPM 不再遵循 Xcode 專案輸出目[……]
蘋果的時間機器確實很有幫助,但大多數時候它只是在後台運行… 直到它通知您備份磁盤已用完. 它保持乾淨, 但免費空間[……]
事到如今,已經很少有運營商願意免費給你公網 IP 了。 CGNAT 早已是常態,當然從好的一方面來看,至少它隱藏了你的真實 IP,一定程度上讓你家裡的路由器/NAS 免受直接的黑客攻擊。
不過如果我想要將 NAS 上的一些服務公開方便出門的時候使用,就成了一個頭疼的問題。最簡單的方法可能就是花錢從運營商那裡買一個靜態 IP,但有的運營商也只提供動態公網IP,還得用 DDNS。用 Cloudflar[……]
懶貓微服 是一個不錯的 nas 系統,CEO 是 Deepin Linux 的作者大佬,機器做工紮實,系統設計創新,值得購買。
對於身處海外的我來說,還是不夠貼近日常使用場景。尤其是他們主打的內網穿透和服務器中轉,以及與梯子配合等等,我都用不到,這麼一來,懶貓系統的價值到我這邊就已經打了對折。再加上 GFW 防火牆雙向干擾,導致鏡像服務器時好時壞。而且由於懶貓的系統是高度定制化的[……]
我有銀河手錶 6 經典的, 現在我剛得到了新的銀河手錶 8, 他們都是LTE版本, 我必須將ESIM移至新手錶. 然而, 足夠長的時間讓我忘記瞭如何確切[……]
有些時候我們需要讓一個域名的訪問重定向到另一個域名,比如舊域名被牆的時候。
有些域名提供商會提供這項服務,但功能非常基礎,只能單純的匹配域名然後做跳轉,而且這種跳轉會丟失參數等信息,或者乾脆就匹配失敗,基本無法使用。
要重定向域名且保留請求參數,就需要你有一個專門的服務器來接受請求然後返回重定向信息。這個需求確實無法單純用 DNS 實現的。
由於我本身有博客服務器,[……]

我家裡的 NAS 其實利用率不高,重要的數據我都是存在雲盤的。不過家裡能有一個媒體中心還是會方便很多……比如看電影的時候。可以後台下載,然後電視等設備能直接讀取。
我之前一直是用一台舊的 rmbp 來做服務器的,放在路由器旁邊,網線直連,這樣下載可以最大化利用帶寬。不過眾所周知 macOS 對 smb 服務的支持很爛,最近趁著有朋友的小主機,就拿它打造了一台 home lab,用的 Prox[……]
Firefly III是一位出色的財務經理, 我用赫斯蒂亞託管. Docker很容易使用,但無論如何我已經讓它運行了以進行自托模式, 因此,這裡還有一些提示[……]
我剛剛解決了設置電子郵件伺服器後的另一個問題, 它無法接收任何傳入的電子郵件. 如果您使用 hotmail 進行測試, 您會收到拒絕通知,說辦公室已在 s 的黑名單中[……]
所以, 你安裝了 Hestia 作為你的控制面板. 你將用它作為你的電子郵件伺服器. 然後你發現沒有垃圾郵件過濾器和clamav,即使你在安裝過程中選擇了它們的選項[……]
之前寫過一篇文章說我 遷移 Plesk 到 Hestia 經過一段時間的使用,除了少了一些功能外,整體還是很穩定實用的。最近我在搗鼓一些 Docker 應用,就發現 赫斯提亞 並不能像 請 那樣直接從 UI 控制和管理 docker,當然,由於 赫斯提亞 本身輕量級的設計架構,我們還是能夠輕易讓它實現 Docker App 反代的,當然了,它確實沒辦法管理 碼頭工人 服務,[……]
最近在做 Android的 版本的落格輸入法,在導入碼表的時候我犯了難。因為落格輸入法的碼表是支援 utf8 和 gb18030 兩種編碼格式的,甚至我自己內建的碼表也是混用這兩種格式的。在 Swift 或 Python 中,如果你使用錯誤的編碼去解碼文本,就會收到報錯。利用這個辦法,我可以輕鬆實現兩種編碼的檢測——先用 utf8 解碼,報錯了就再試試 gb18030. 簡單方便,足夠我用。[……]
我最近切換運營商,新的運營商提供給我的是一個 /48 的地址前綴,這和我之前的營運商們不一樣,他們大多使用 DHCP,直接給你分配一個 IPv6的 的地址。儘管 v6 存在的意義就是地址“無限”,但分配一個的話能省掉很多配置上的麻煩事。
這次全新的設定讓我措手不及。
好消息是,官方有教程。壞消息是,官方的教學不沃克。
這就有些讓人頭痛了,設定完沒網,即使我手動為路由器新增了靜態路由到出口,[……]

通常來說,可能不是很多人會遇到這種情況,就是你想要更換信箱,但又需要將目前信箱的郵件帶過去。但一旦發生,你就會發現,一個和互聯網幾乎相同年齡的東西,居然沒有一個成熟的匯出和匯入功能。
比這更令人頭痛的是,如果你是一個郵件伺服器管理員,你就悲慘的發現,有伺服器權限也不行。郵箱裡的內容是使用特殊各式存放的,它不是一個簡單的資料庫,需要使用相應的服務進行存取,直接移動檔案很可能導致資料損壞,得不[……]

使用 AWS 光帆 + 請 的小夥伴可能都已經聽說了,Plesk 決定取消雲端平台合作免費 3 網域授權了。我的兩個域名,其中一個網域下還掛了兩個子網域網站,剛好可以用這個授權,現在也需要付費了。
去官網一看,最便宜的授權是 10 域名,$169.5 美元一年! 好吧,就算加上半價促銷,也只是第一年半價,我實際上只用兩個域名,實在是不划算。於是就想還是換個面板吧。[……]
最近有機會試用三星的 Dex 模式,遇到一個頭痛的問題。我平常輸入中文使用雙拼,而三星鍵盤是不支援雙拼的。僅安裝第三方鍵盤 Google keyboard。但在 Dex 上,雖然設定中已經自動添加了Google鍵盤,但實際使用時只能呼叫三星自己的鍵盤。
解決的辦法也很簡單,就是刪掉三星鍵盤即可。我沒有試過裝有多個第三方鍵盤的情況,就我自己來說,刪掉三星鍵盤後,由於我只有Google鍵盤,谷歌鍵盤自動變成[……]